本文讨论了缓存与数据库不一致问题,探讨了几种常见解决思路。 列举了分布式缓存高可用的几种解决方案,以及应对缓存穿透的常见思路。
目录
缓存是什么,解决了什么问题
一般来说,用来协调速度相差较大的两种硬件之间数据传输速度差异的结构,让数据更快的返回,都可称为缓存。
不同硬件之间读写速度差异
Latency Comparison Numbers (~2012)
----------------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 3,000 ns 3 us
Send 1K bytes over 1 Gbps network 10,000 ns 10 us
Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns一个简单的更新操作
有一个用户表,需要把 小明(ID = 1)的身高从 170 修改为 180。
如果更新步骤为:
- 更新数据库
- 更新缓存
那么,有可能会造成缓存和数据库数据不一致
比如同时两个请求 A、B 请求 A 希望把小明(ID = 1)的身高从 170 修改为 180 请求 B 希望把小明(ID = 1)的身高从 170 修改为 181
步骤为:
- 请求 A 把数据库 ID = 1 的身高修改为 180
- 请求 B 把数据库 ID = 1 的身高修改为 181
- 请求 B 把缓存 ID = 1 的身高修改为 181
- 请求 A 把缓存 ID = 1 的身高修改为 180
此时,数据库中小明身高为 181, 缓存中小明身高为 180, 缓存和数据库数据不一致
旁路缓存 Cache Aside 策略
解决并发情况下缓存和数据库字段一致,主要用于不经常变化的数据, “一写多读” 场景
读策略的步骤是: 从缓存中读取数据; 如果缓存命中,则直接返回数据; 如果缓存不命中,则从数据库中查询数据; 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是: 更新数据库中的记录; 删除缓存记录。
可否调换写策略步骤顺序
不可,假设: 请求 A 希望把小明(ID = 1)的身高从 170 修改为 180 请求 B 希望查询小明(ID = 1)的身高
操作顺序是:
- 请求 A 删除缓存
- 请求 B 查询缓存,未命中
- 请求 B 查询数据库,得到身高 170
- 请求 B 写入缓存,缓存中小明身高 170
- 请求 A 更新数据库,数据库中小明身高 180
此时,又造成缓存和数据库的不一致。
先更新,后删除,就万无一失了吗?
并没有,有一种概率较小的情况 请求 A 希望把小明(ID = 1)的身高从 170 修改为 180 请求 B 希望查询小明(ID = 1)的身高
操作顺序是:
- 请求 B 查询缓存,未命中
- 请求 B 查询数据库,得到身高 170
- 请求 A 更新数据库,数据库中小明身高 180
- 请求 A 删除缓存
- 请求 B 写入缓存,缓存中小明身高 170
概率小是因为,一般缓存的写入速度,是快于数据库写入的,所以,在做完 3、4 才完成 5 的概率很小。
更多优化思路
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。 如果业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 使用分布式锁,在更新数据时也更新缓存。因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快地过期,对业务的影响也是可以接受。
Write Through、Read Through 及 Write Back 策略
Write Through(写穿) 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做 “Write Miss(写失效)”。
Read Through(读穿) 策略就步骤是这样的:先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据。
Write Back(写回)策略 这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为 “脏” 的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。
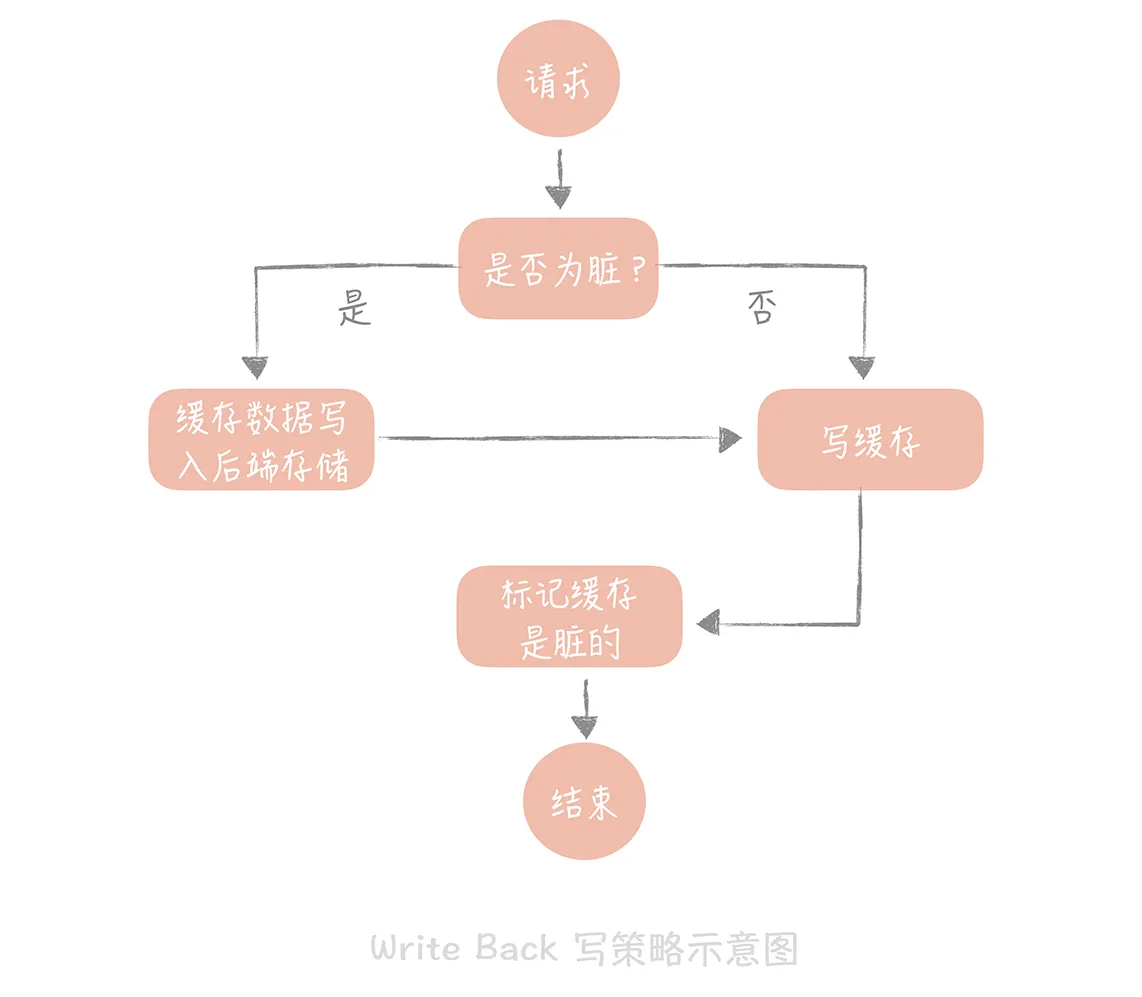
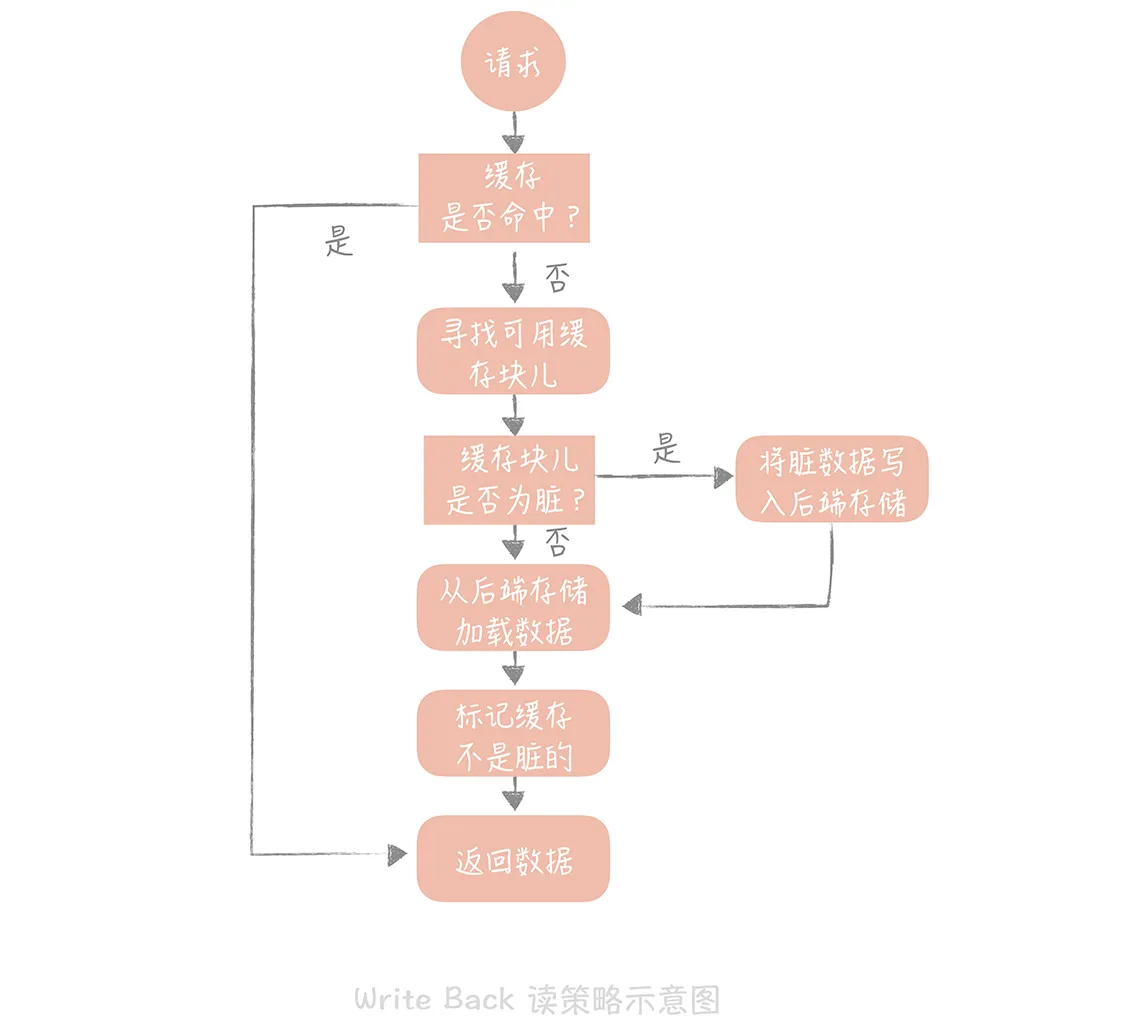
操作系统中往磁盘中写数据时采用的就是这种策略。应用场景有 Page Cache,还是日志的异步刷盘、消息队列中消息的异步写入磁盘等。
分布式缓存的高可用方案
客户端方案就是在客户端配置多个缓存的节点,通过缓存写入和读取算法策略来实现分布式,从而提高缓存的可用性。 中间代理层方案是在应用代码和缓存节点之间增加代理层,客户端所有的写入和读取的请求都通过代理层,而代理层中会内置高可用策略,帮助提升缓存系统的高可用 服务端方案就是 Redis 2.4 版本后提出的 Redis Sentinel 方案。
客户端方案
缓存数据如何分片
单一的缓存节点受到机器内存、网卡带宽和单节点请求量的限制,不能承担比较高的并发 可以将数据分片,依照分片算法将数据打散到多个不同的节点上,每个节点上存储部分数据。 同时也可以在某个节点故障的情况下,其他节点也可以提供服务,保证了一定的可用性。
一般来讲,分片算法常见的就是 Hash 分片算法和一致性 Hash 分片算法两种。
Hash 分片算法
Hash 分片的算法就是对缓存的 Key 做哈希计算,然后对总的缓存节点个数取余 优点:简单易理解 缺点:当增加或者减少缓存节点时,缓存总的节点个数变化造成计算出来的节点发生变化,从而造成缓存失效不可用 建议:如果采用这种方法,最好建立在对于这组缓存命中率下降不敏感的情况下,比如下面还有另外一层缓存来兜底。
一致性 Hash 分片算法
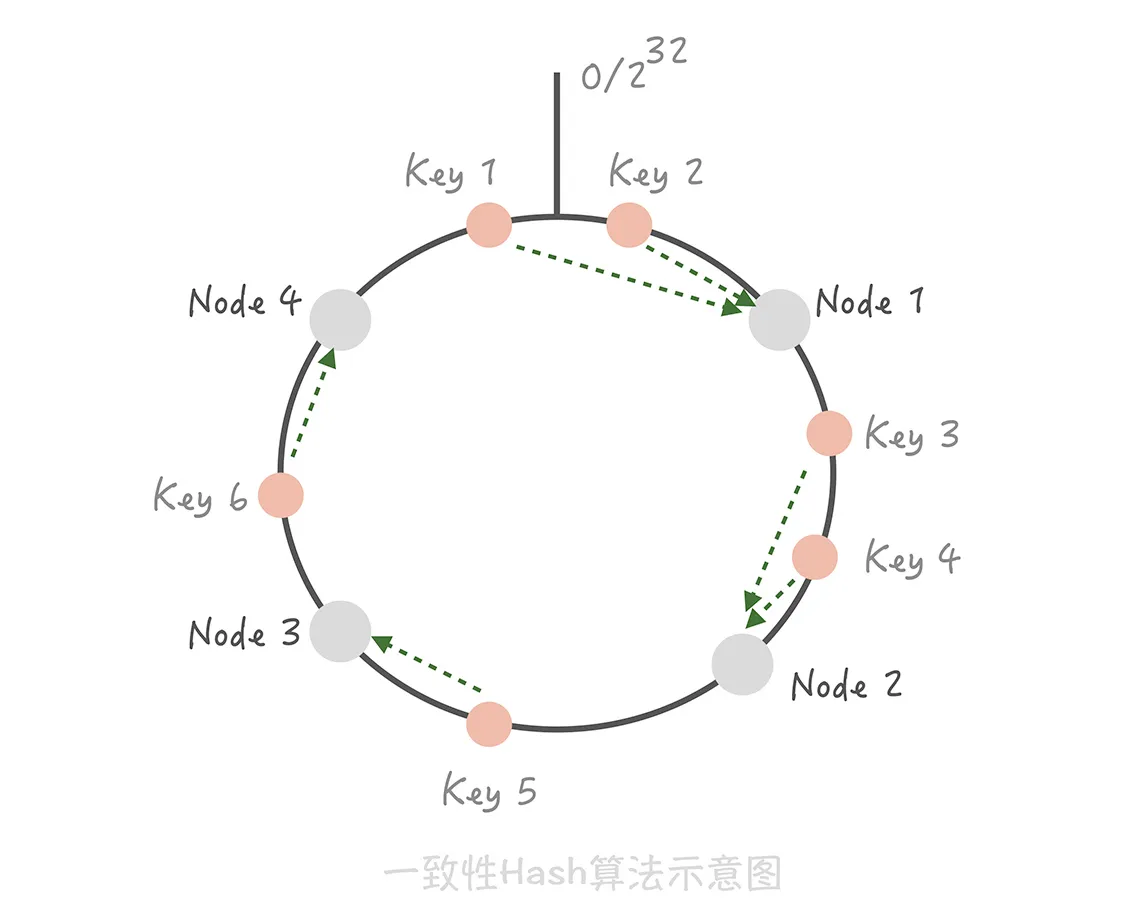
一致性 Hash 算法可以很好地解决增加和删减节点时,命中率下降的问题
将整个 Hash 值空间组织成一个虚拟的圆环,然后将缓存节点的 IP 地址或者主机名做 Hash 取值后,放置在这个圆环上。 当需要确定某一个 Key 需要存取到哪个节点上的时候,先对这个 Key 做同样的 Hash 取值, 确定在环上的位置,然后按照顺时针方向在环上 “行走”,遇到的第一个缓存节点就是要访问的节点。
比方说下面这张图里面,Key1 和 Key2 会落入到 Node1 中,Key3、Key4 会落入到 Node2 中,Key5 落入到 Node3 中,Key6 落入到 Node4
中。
这时如果在 Node1 和 Node2 之间增加一个 Node5,原本命中 Node 的 Key3 现在命中到 Node5,而其它的 Key 都没有变化;
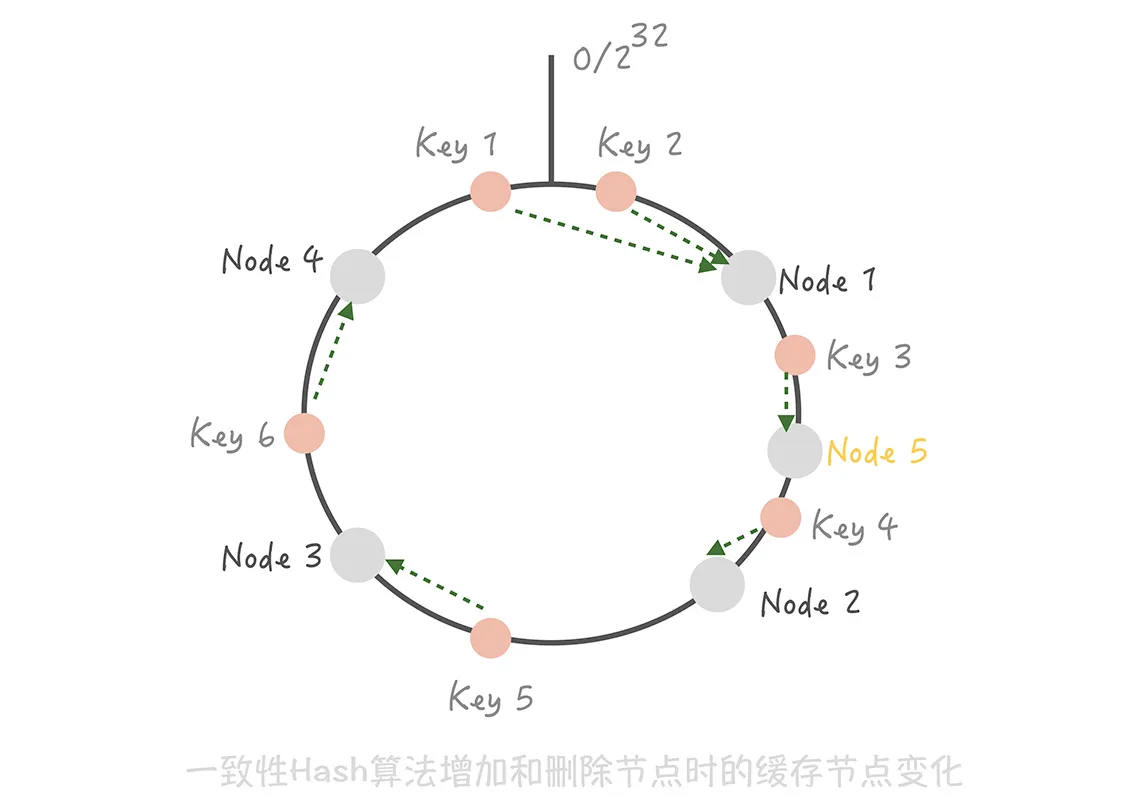
优点: 在增加和删除节点时,只有少量的 Key 会 “漂移” 到其它节点上,而大部分的 Key 命中的节点还是会保持不变,从而可以保证命中率不会大幅下降。 缺点:
-
缓存节点在圆环上分布不平均,会造成部分缓存节点的压力较大;当某个节点故障时,这个节点所要承担的所有访问都会被顺移到另一个节点上,会对后面这个节点造成压力。 (解决方法,引入虚拟节点的概念)
-
一致性 Hash 算法的脏数据问题。
-
产生原因: 集群中有两个节点 A、B,客户端在 写入 key 计算后需要更新到 A 节点,值为 3, 更新成功后 A 节点和客户端连接出现问题,下一次更新到了 B 节点,值为 4, 客户端和 A 节点重连,获取 key 值时,得到的是 A 节点的结果 3,出现脏数据
-
解决方法:设置缓存的过期时间,这样当发生漂移时,之前存储的脏数据可能已经过期,就可以减少存在脏数据的几率。
-
中间代理层方案
客户端方案中,只能在单一语言中复用代码(如使用java实现后,python 项目无法直接使用),中间代理层方案主要解决了这个问题
自己实现 or 第三方 Facebook 的 Mcrouter,Twitter 的 Twemproxy,豌豆荚的 Codis。
服务端方案
Redis 在 2.4 版本中提出了 Redis Sentinel(哨兵)模式来解决主从 Redis 部署时的高可用问题,它可以在主节点挂了以后自动将从节点提升为主节点。
缓存穿透
是什么
从缓存中没有查到数据,而不得不从后端系统(比如数据库)中查询的情况。
少量的缓存穿透不可避免,对系统也是没有损害的,一般来说,互联网数据访问也遵循二八法则,最重要的事物通常只占 20%(热点数据),而剩余的 80% 的事物确实不重要的。
如果大量的穿透请求超过了后端系统的承受范围,会造成后端系统的崩溃。接下来,将探讨如何规避这种大量缓存穿透问题。
解决方案
场景:使用前文「旁路缓存 Cache Aside 策略」
- 读缓存,未命中
- 查数据库,未查到
- 不会向缓存中写入值,返回
- 再次请求,进入步骤 1
回种空值
方案: 在步骤 3 中把空值写入缓存,设置较短的超时时间
缺点:但如果有大量未命中的请求,缓存内就会有有大量的空值缓存,也就会浪费缓存的存储空间,如果缓存被占满,还会「挤掉」正常的缓存,导致命中率下降。 使用的时候应该评估一下缓存容量是否能够支撑
使用布隆过滤器
布隆过滤器基本思路如下:
- 把集合中的每一个值按照提供的 Hash 算法算出对应的 Hash 值
- 将 Hash 值对数组长度取模后得到需要计入数组的索引值,并且将数组这个位置的值从 0 改成 1
- 判断一个元素是否存在于这个集合中时,将这个元素按照相同的算法计算出索引值
- 如果这个位置的值为 1 就认为这个元素在集合中,否则则认为不在集合中
使用方法:
- 新写入的数据,写入数据库,并依照同样的算法更新布隆过滤器的数组中,相应位置的值。
- 查询时,先查询在布隆过滤器中是否存在,如果不存在就直接返回空值
优点: 布隆过滤器性能很好,无论是写入操作还是读取操作,时间复杂度都是 O(1)
缺点:
- 在判断元素是否在集合中时是有一定错误几率的,比如它会把不是集合中的元素判断为处在集合中;
- 不支持删除元素。
第一个缺点主要是 hash 算法的问题,存在一定碰撞几率。 但是一旦布隆过滤器判断这个元素不在集合中时,它一定不在集合中。这一点非常适合解决缓存穿透的问题。 一个解决方案: 使用多个 Hash 算法为元素计算出多个 Hash 值,只有所有 Hash 值对应的数组中的值都为 1 时,才会认为这个元素在集合中。
布隆过滤器不支持删除元素的缺陷也和 Hash 碰撞有关。 比如,两个元素 A 和 B 都是集合中的元素,它们有相同的 Hash 值,如果删除 A,把数组的相应位置从 1 变成 0,那么在判断 B 的时候发现值是 0,也会判断 B 是不在集合中的元素,就会得到错误的结论。 解决方案: 数组中不再只有 0 和 1 两个值,而是存储一个计数。比如如果 A 和 B 同时命中了一个数组的索引,那么这个位置的值就是 2,如果 A 被删除了就把这个值从 2 改为 1。这个方案中的数组不再存储 bit 位,而是存储数值,也就会增加空间的消耗。 (根据业务场景灵活选择)
其它场景
回种空值和布隆过滤器是解决缓存穿透问题的两种最主要的解决方案,但是它们也有各自的适用场景,并不能解决所有问题。
比如当有一个极热点的缓存项,它一旦失效会有大量请求穿透到数据库,这会对数据库造成瞬时极大的压力,我们把这个场景叫做 “dog-pile effect”(狗桩效应),
这是典型的缓存并发穿透的问题,那么,我们如何来解决这个问题呢?解决狗桩效应的思路是尽量地减少缓存穿透后的并发,方案也比较简单:
-
在代码中,控制在某一个热点缓存项失效之后启动一个后台线程,穿透到数据库,将数据加载到缓存中,在缓存未加载之前,所有访问这个缓存的请求都不再穿透而直接返回。
-
通过在 Memcached 或者 Redis 中设置分布式锁,只有获取到锁的请求才能够穿透到数据库。
静态资源加速
使用 CDN。 静态资源访问的关键点是就近访问,即北京用户访问北京的数据,杭州用户访问杭州的数据,这样才可以达到性能的最优。 CDN 就是将静态的资源分发到,位于多个地理位置机房中的服务器上。
-
第三方厂商的 CDN 厂商会给我们一个 CDN 的节点 IP,为防止更换 CDN 厂商造成的 IP 变动,使用 DNS 来解决域名映射问题。
-
因为域名解析过程是分级的,每一级有专门的域名服务器承担解析的职责,所以,域名的解析过程有可能需要跨越公网做多次 DNS 查询,在性能上是比较差的。 解决思路: 启动时,对需要解析的域名做预先解析,然后把解析的结果缓存到本地的一个 LRU 缓存里面。
-
GSLB 可以给用户返回一个离着他更近的节点,加快静态资源的访问速度。
完结,撒花。