- OpenResty 学习笔记(目录)
- OpenResty 学习笔记(2) - 前置知识
- OpenResty 学习笔记(3) - LuaJIT
- OpenResty 学习笔记(4) - OpenResty 原理和 API
- OpenResty 学习笔记(5) - shared dict、cosocket、特权进程
- OpenResty 学习笔记(6) - 测试工具
- OpenResty 学习笔记(7) - 性能优化和编码指南
- OpenResty 学习笔记(8) - 动态调试
目录
动态调试
测试环境稳定复现
打日志
线上才可复现
如果是线上环境才会复现的 bug,是否有调试的方法呢?
推荐一个工具 —— Mozilla RR,可以把它当作是一个复读机,可以把程序的行为录制下来,然后反复地重放。
如何定位问题在哪个组件?
土方法:二分注释代码
正经可视化方法: OpenTracing、Zipkin、Apache SkyWalking
OpenTracing 可以在系统的各处埋点,通过 Trace ID 把多个 Span 组成的调用链和埋点数据上报到服务端,进行分析和图形化的展现。这样就可以发现很多隐藏的问题,而且历史数据都会保存下来,方便我们随时对比和查看。
另外,如果你的系统比较复杂,比如是在微服务的环境下,那么 Zipkin、Apache SkyWalking 都是不错的选择。
线上偶现 bug
Dtrace,专门用于动态调试。
动态调试,也叫做活体调试。和 GDB 这种静态调试工具不同,动态调试可以调试线上的服务,而对调试的程序而言,整个调试过程是无感知、无侵入的,不用你修改代码,更不用重启。打一个比方,动态调试就像 X 光,可以在病人无感知的情况下检查身体,而不需要抽血和胃镜。
Systemtap,这个重要
Systemtap
安装
sudo apt install systemtapSystemtap 的 hello world
# cat hello-world.stp
probe begin
{
print("hello world!")
exit()
}需要使用 sudo 权限才可以运行:
sudo stap hello-world.stp在大部分场景下,我们都不需要自己写 stap 脚本来进行分析,因为 OpenResty 已经有了很多现成的 stap 脚本来做常规的分析。
probe 就是一个探针。begin 会在探测的最开始运行,与之对应的是 end,所以上面的 hello world 程序也可以写成下面的这种方式:
probe begin
{
print("hello ")
exit()
}
probe end
{
print("world!")
}了解更多,推荐阅读: 《Systemtap tutorial》。
当然,对于内核和性能分析工程师来说,只有 Systemtap 还是不够用的。首先, Systemtap 并没有默认进入系统内核;其次,它的工作原理决定了它的启动速度比较慢,而且有可能对系统的正常运行造成影响。
在 OpenResty 中有两个开源项目:openresty-systemtap-toolkit 和 stapxx 。它们是基于 Systemtap 封装好的工具集,用于 Nginx 和 OpenResty 的实时分析和诊断。它们可以覆盖 on CPU、off CPU、共享字典、垃圾回收、请求延迟、内存池、连接池、文件访问等常用的功能和调试场景。
(这两个已经很久不维护了,项目开发者去开发维护 OpenResty XRay 了,花钱买服务或者自强吧)
其他动态追踪框架
eBPF(extended BPF)则是最近几年 Linux 内核中新增的特性。相比 Systemtap,eBPF 有内核直接支持、不会死机、启动速度快等优点;同时,它并没有使用 DSL,而是直接使用了 C 语言的语法,所以也大大降低了它的上手难度。
VTune 也可以尝试
火焰图
perf 和 Systemtap 等工具产生的数据,都可以通过火焰图的方式,来进行更加直观的展示。下面这张图就是火焰图的示例:
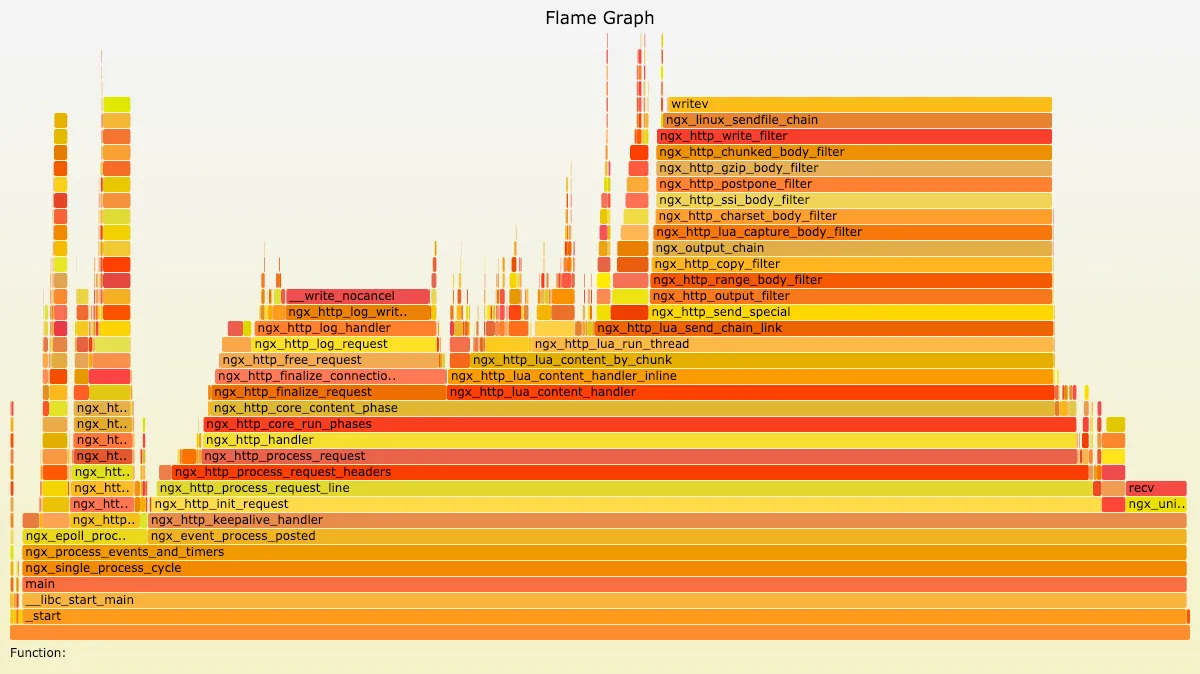
在火焰图中,色块的颜色和深浅都是没有意义的,只是为了对不同的色块儿做出简单的区分。火焰图其实是把每次采样的数据进行叠加,所以,真正有意义的是色块的宽度和长度。
对于 on CPU 火焰图来说,色块的宽度是函数占用的 CPU 时间百分比,色块越宽,则说明性能消耗越大。如果出现一个平顶的山峰,那它就是性能的瓶颈所在。而色块的长度,代表的是函数调用的深度,最顶端的框显示正在运行的函数,在它之下的都是这个函数的调用者。所以,在下面的函数是上面函数的父函数,山峰越高,则说明调用的函数层级越深。
OpenResty 动态加载代码
loadstring
resty -e 'local s = [[ngx.say("hello world")]]
local func, err = loadstring(s)
func()'- 首先,声明了一个字符串,它的内容是一段合法的 Lua 代码,把
hello world打印出来; - 然后,使用 Lua 中的
loadstring函数,把字符串对象转为函数对象func; - 最后,在函数名的后面加上括号,把
func执行起来,打印出hello world来。
loadfile 可以加载指定的文件 loadfile("foo.lua")
基于此可以扩展出如下功能
功能一:FaaS
FaaS 函数即服务
local s = [[
return function()
ngx.say("hello world")
end
]]函数在 Lua 中是一等公民,这段代码便是返回了一个匿名函数。在执行这个匿名函数时,我们使用 pcall 做了一层保护。pcall 会在保护模式下运行函数,并捕获其中的异常,如果正常就返回 true 和执行的结果,如果失败就返回 false 和错误信息,也就是下面这段代码:
local func1, err = loadstring(s)
local ret, func = pcall(func1)把上面的两部分结合起来,就会得到完整的、可运行的示例:
resty -e 'local s = [[
return function()
ngx.say("hello world")
end
]]
local func1 = loadstring(s)
local ret, func = pcall(func1)
func()'更深入一步,我们还可以把 s 这个包含函数的字符串,改成可以由用户指定的形式,并加上执行它的条件,这样其实就是 FaaS 的原型了, Apisix 的实现。
功能二:边缘计算
得益于 Nginx 和 LuaJIT 良好的多平台支持特性,OpenResty 不仅能运行在 X86 架构下,对于 ARM 的支持也很完善。同时, OpenResty 支持七层和四层的代理,这样一来,常见的各种协议都可以被 OpenResty 解析和代理,这其中也包括了 IoT 中的几种协议。
因为这些优势,我们便可以把 OpenResty 部署到,联网设备、CDN 边缘节点、路由器等最靠近用户的边缘节点上去。
以 CDN 的边缘节点为例,OpenResty 的最大使用者 CloudFlare 很早就借助 OpenResty 的动态特性,实现了对于 CDN 边缘节点的动态控制。
CloudFlare 的做法和上面动态加载代码的原理是类似的,大概可以分为下面几个步骤:
- 首先,从键值数据库集群中获取到有变化的代码文件,获取的方式可以是后台 timer 轮询,也可以是用“发布-订阅”的模式来监听;
- 然后,用更新的代码文件替换本地磁盘的旧文件,然后使用
loadstring和pcall的方式,来更新内存中加载的缓存;
这样,下一个被处理的终端请求,就会走更新后的代码逻辑。
当然,实际的应用要比上面的步骤考虑更多的细节,比如版本的控制和回退、异常的处理、网络的中断、边缘节点的重启等,但整体的流程是不变的。
动态上游
lua-resty-core 提供了 ngx.balancer 这个库来设置上游,它需要放到 OpenResty 的 balancer 阶段来运行:
balancer_by_lua_block {
local balancer = require "ngx.balancer"
local host = "127.0.0.2"
local port = 8080
local ok, err = balancer.set_current_peer(host, port)
if not ok then
ngx.log(ngx.ERR, "failed to set the current peer: ", err)
return ngx.exit(500)
end
}set_current_peer 函数,就是用来设置上游的 IP 地址和端口的。不过要注意,这里并不支持域名,需要使用 lua-resty-dns 库来为域名和 IP 做一层解析。
不过,ngx.balancer 还比较底层,虽然它有设置上游的能力,但动态上游的实现远非如此简单。所以,在 ngx.balancer 前面还需要两个功能:
- 一是上游的选择算法,究竟是一致性哈希,还是 roundrobin;
- 二是上游的健康检查机制,这个机制需要剔除掉不健康的上游,并且需要在不健康的上游变健康的时候,重新把它加入进来。
而 OpenResty 官方的 lua-resty-balancer 这个库中,则包含了 resty.chash 和 resty.roundrobin 两类算法来完成第一个功能,并且有 lua-resty-upstream-healthcheck 来尝试完成第二个功能。
不过,这其中还是有两个问题。
第一点,缺少最后一公里的完整实现。把 ngx.balancer、lua-resty-balancer 和 lua-resty-upstream-healthcheck 整合并实现动态上游的功能,还是需要一些工作量的,这就拦住了大部分的开发者。
第二点,lua-resty-upstream-healthcheck 的实现并不完整,只有被动的健康检查,而没有主动的健康检查。
简单解释一下,这里的被动健康检查,是指由终端的请求触发,进而分析上游的返回值来作为健康与否的判断条件。如果没有终端请求,那么上游是否健康就无从得知了。而主动健康检查就可以弥补这个缺陷,它使用 ngx.timer 定时去轮询指定的上游接口,来检测健康状态。
通常推荐使用 lua-resty-healthcheck 这个库,来完成上游的健康检查。它的优点是包含了主动和被动的健康检查,而且在多个项目中都经过了验证,可靠性更高。
APISIX 的实现。
OpenResty 常用的第三方库
首选去awesome-resty 仓库寻找,还可以去 luarocks、opm 和 GitHub 碰碰运气。有一些开源时间不长的、或者关注不多的库,可能就藏在其中。
搭建 API 网关
API 网关功能概览
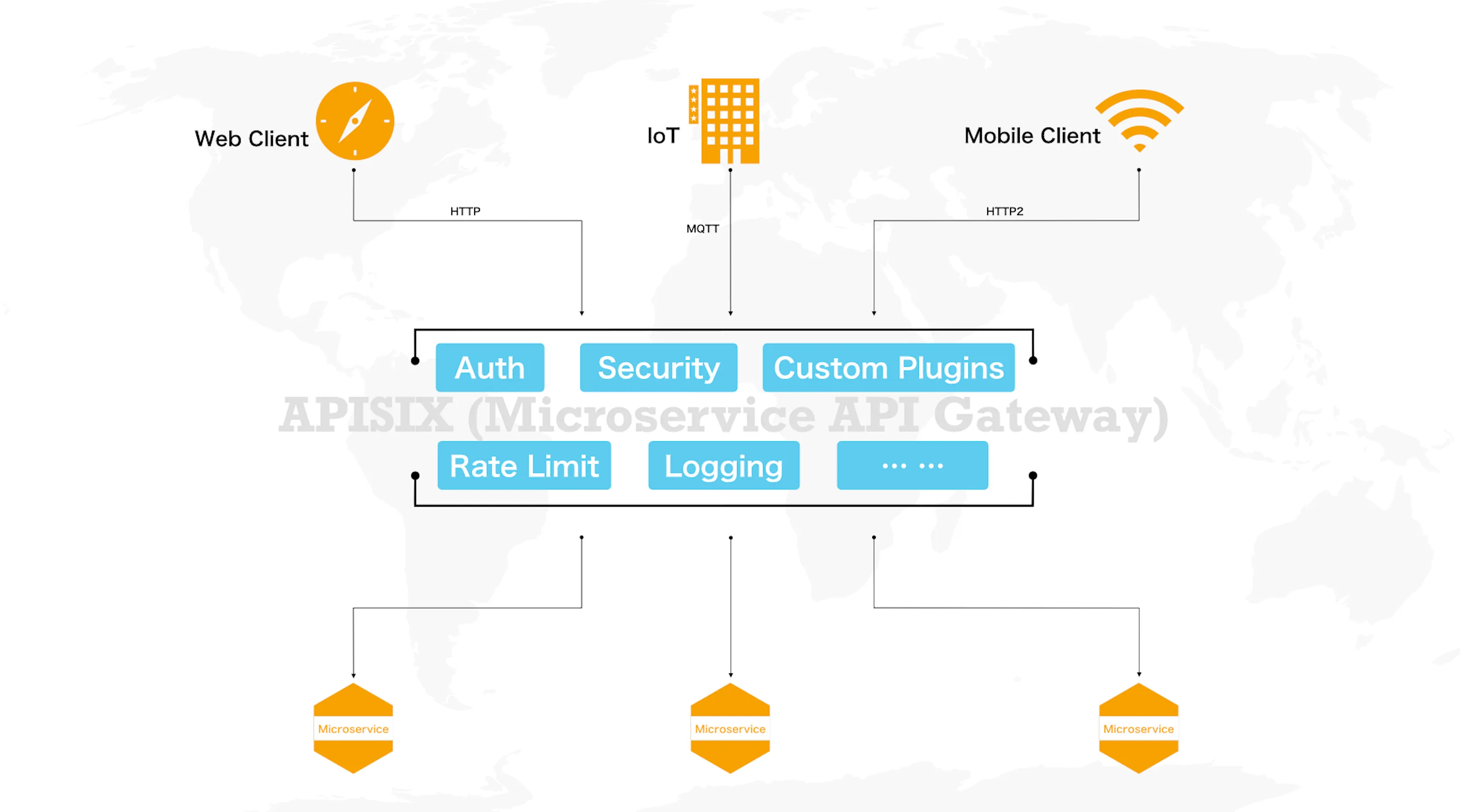
-
路由。它通过定义一些规则来匹配客户端的请求,然后根据匹配结果,加载、执行相应的插件,并把请求转发给到指定的上游。这些路由匹配规则可以由 host、uri、请求头等组成,我们熟悉的 Nginx 中的 location,就是路由的一种实现。
-
插件。这是 API 网关的灵魂所在,身份认证、限流限速、IP 黑白名单、Prometheus、Zipkin 等这些功能,都是通过插件的方式来实现的。既然是插件,那就需要做到即插即用;并且,插件之间不能互相影响,就像我们搭建乐高积木一样,需要用统一规则的、约定好的开发接口,来和底层进行交互。
-
schema。既然是处理 API 的网关,那么少不了要对 API 的格式做校验,比如数据类型、允许的字段内容、必须上传的字段等,这时候就需要有一层 schema 来做统一、独立的定义和检查。
-
存储。它用于存放用户的各种配置,并在有变更时负责推送到所有的网关节点。这是底层非常关键的基础组件,它的选型决定了上层的插件如何编写、系统能否保持高可用和可扩展性等,所以需要我们审慎地决定。
另外,在这些核心组件之上,我们还需要抽象出几个 API 网关的常用概念,它们在不同的 API 网关之间都是通用的。
Route。路由会包含三部分内容,即匹配的条件、绑定的插件和上游
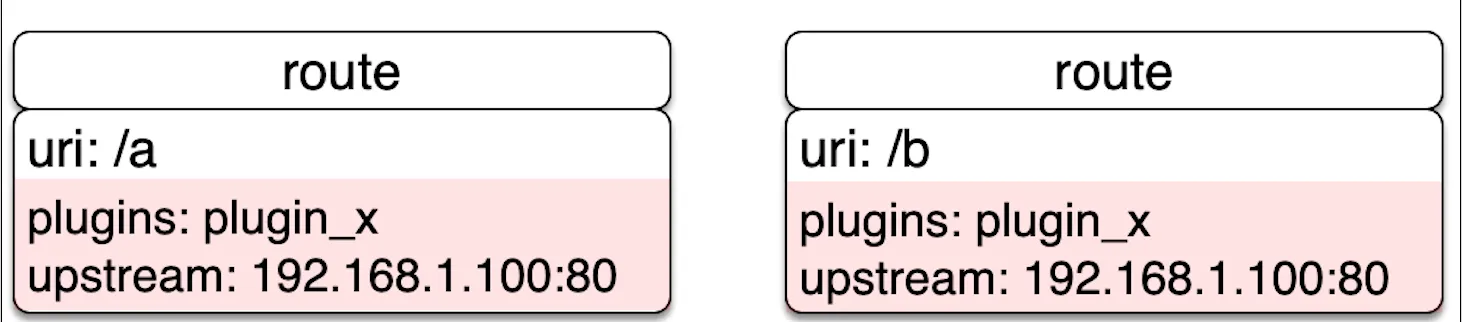
我们可以直接在 Route 中完成所有的配置,这样最简单。但在 API 和上游很多的情况下,这样做就会有很多重复的配置。这时候,我们就需要 Service 和 Upstream 这两个概念来做一层抽象。
-
Service。它是某类 API 的抽象,也可以理解为一组 Route 的抽象,它通常与上游服务是一一对应的,而 Route 与 Service 之间通常是 N:1 的关系。
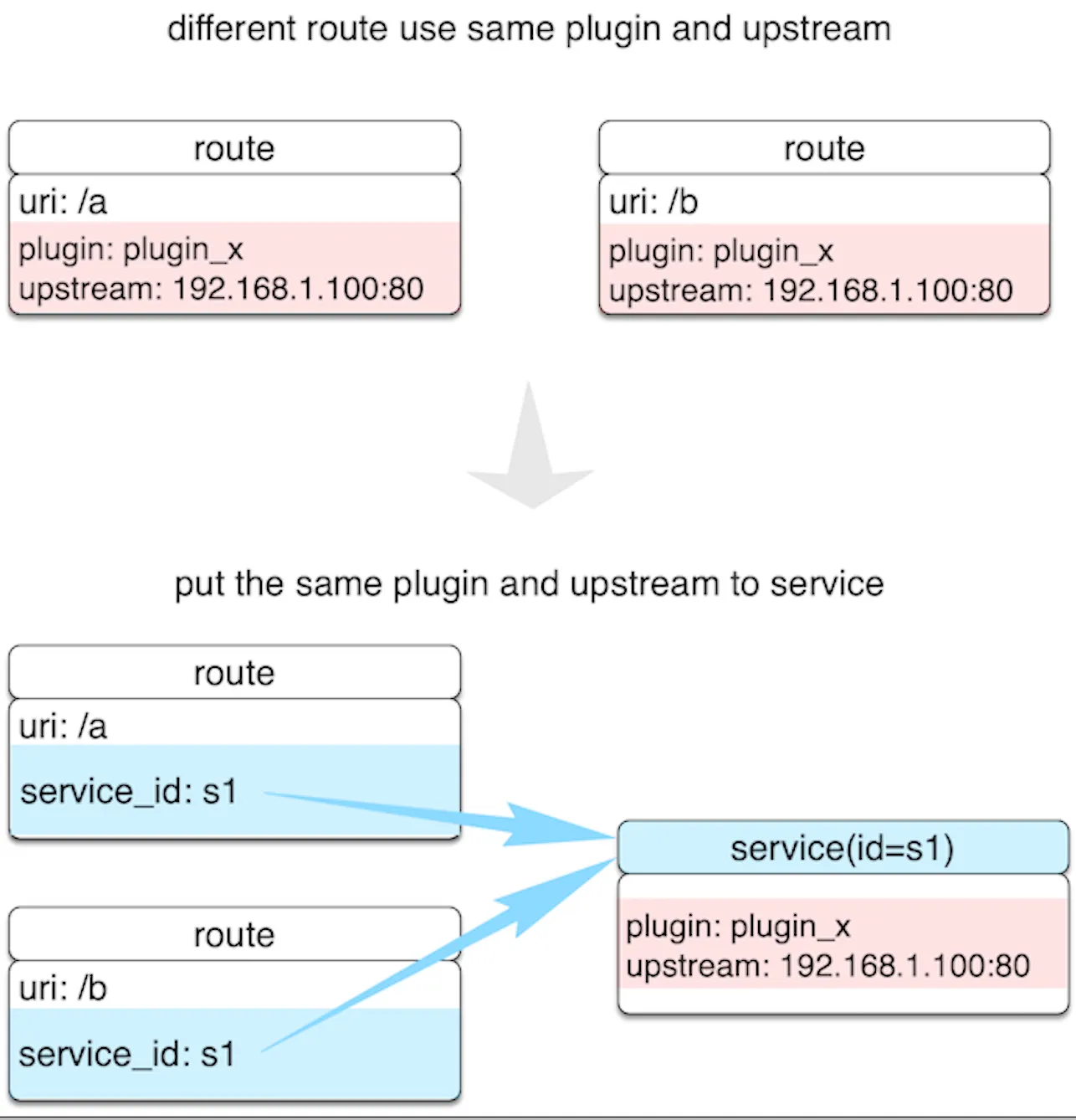
通过 Service 的这层抽象,我们就可以把重复的插件和上游剥离出来。这样,在插件和上游发生变更的时候,我们只需要修改 Service 就可以了,而不用去修改多个 Route 上绑定的数据。
-
Upstream。
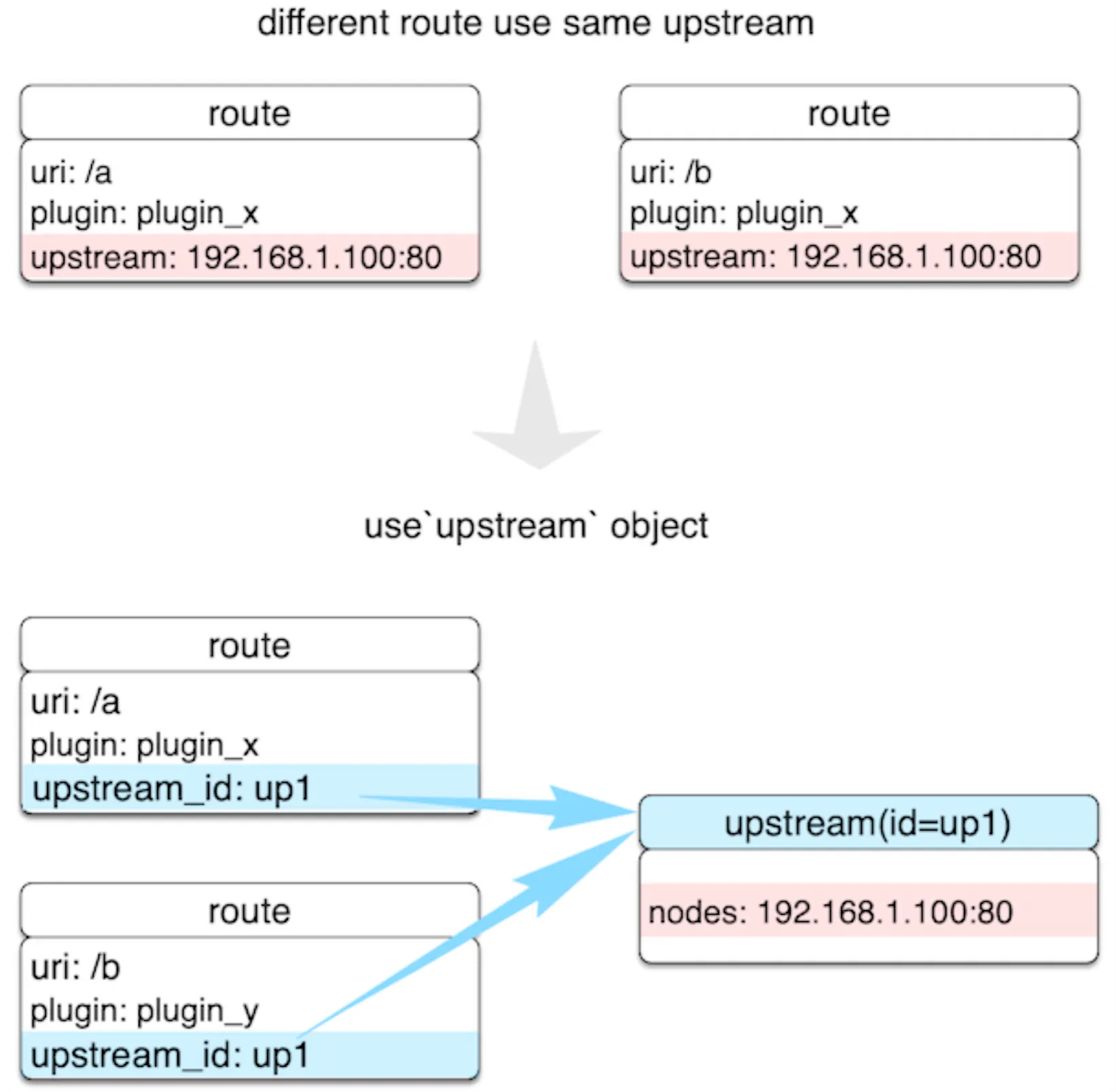
这样,在上游节点发生变更时,Route 是完全无感知的,它们都在 Upstream 内部进行了处理。
核心组件设计
存储
Kong 是把数据储存在 PostgreSQL 或者 Cassandra 中,而同样基于 OpenResty 的 Orange,则是存储在 MySQL 中。缺点:
- 储存需要单独做高可用方案。需要 DBA 和机器资源,在发生故障时也很难做到快速切换。
- 只能轮询数据库来获取配置变更,无法做到推送。
- 需要自己维护历史版本,并考虑回退和升级。系统升级时候可能会修改表结构,代码层面需要考虑新旧版本兼容。回归需要自己在两个版本直接做 diff。
- 提高了代码的复杂度。需要为上面的三个缺陷打补丁,代码可读性会因此下降不少
- 增加了部署和运维的难度。难以快速扩缩容。
etcd 就是一个恰到好处的选型了:
- API 网关的配置数据每秒钟的变化次数不会很多,etcd 在性能上是足够的;
- 集群和动态伸缩方面,更是 etcd 天生的优势;
- etcd 还具备 watch 的接口,不用轮询去获取变更。
路由
lua-resty-radixtree 支持根据 uri、host、http method、http header、Nginx 变量、IP 地址等多个维度,作为路由查找的条件;同时,基数树的时间复杂度为 O(K),性能远比现有 API 网关常用的“遍历+hash 缓存”的方式,来得更为高效。
local radix = require("resty.radixtree")
local rx = radix.new({
{
path = "/aa",
host = "foo.com",
method = {"GET", "POST"},
remote_addr = "127.0.0.1",
},
{
path = "/bb*",
host = {"*.bar.com", "gloo.com"},
method = {"GET", "POST", "PUT"},
remote_addr = "fe80:fe80::/64",
vars = {"arg_name", "jack"},
}
})
ngx.say(rx:match("/aa", {host = "foo.com",
method = "GET",
remote_addr = "127.0.0.1"
}))schema
lua-resty-jsonschema
local jsonschema = require 'jsonschema'
-- Note: Cache the result of the schema compilation as this is quite expensive
local myvalidator = jsonschema.generate_validator {
type = 'object',
properties = {
foo = { type = 'string' },
bar = { type = 'number' },
},
}
print(myvalidator{ foo='hello', bar=42 })插件
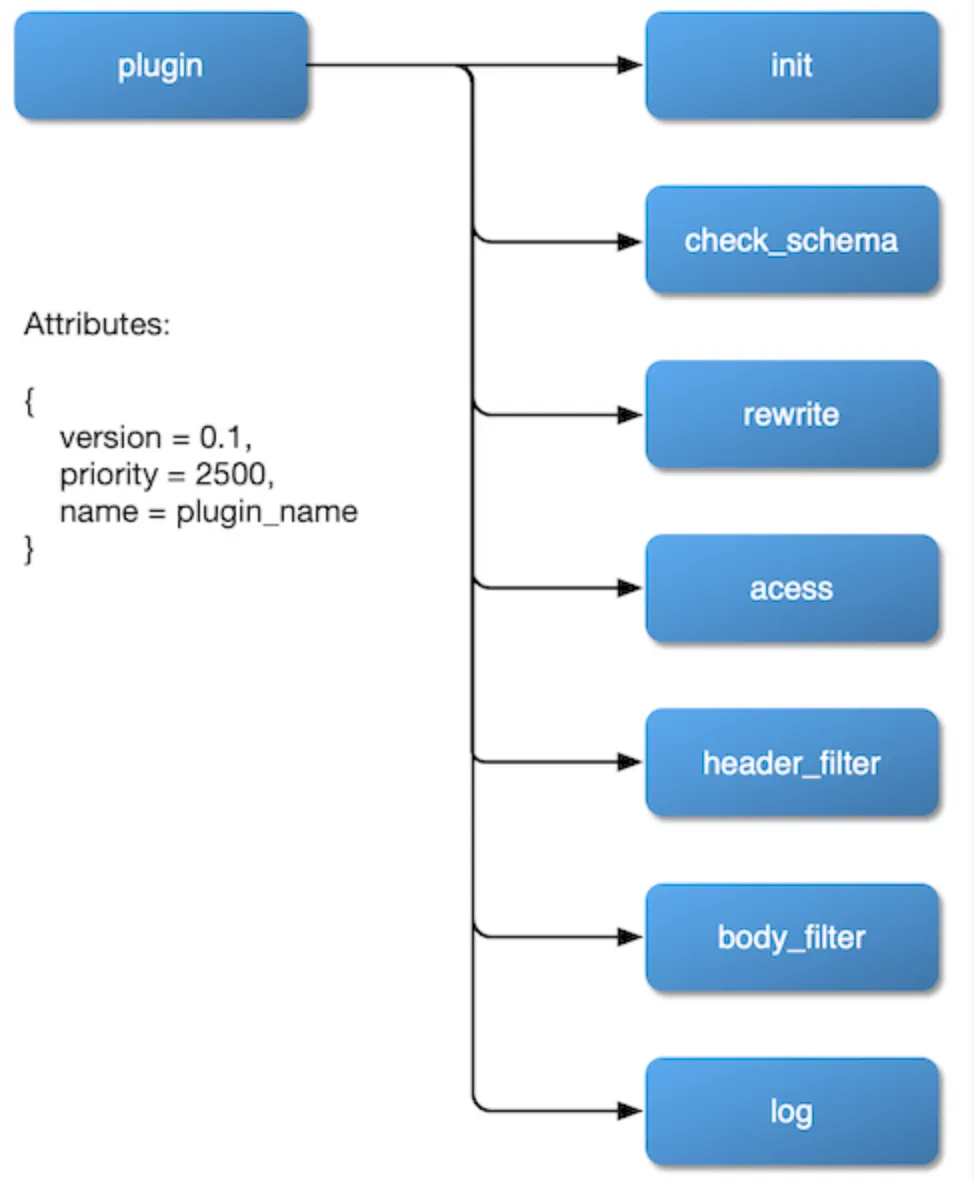
插件在设计的时候,主要有三个方面需要我们考虑清楚。
-
如何挂载。我们希望插件可以挂载到
rewrite、access、header filer、body filter和log阶段,甚至在balancer阶段也可以设置自己的负载均衡算法。所以,我们应该在 Nginx 的配置文件中暴露这些阶段,并在对插件的实现中预留好接口。 -
如何获取配置的变更。由于没有关系型数据库的束缚,插件参数的变更可以通过 etcd 的 watch 来实现,这会让整体框架的代码逻辑变得更加明了易懂。
-
插件的优先级。具体来说,比如,身份认证和限流限速的插件,应该先执行哪一个呢?绑定在 route 和绑定在 service 上的插件发生冲突时,又应该以哪一个为准呢?这些都是我们需要考虑到位的。
插件内部的一个流程图
架构
当微服务 API 网关的这些关键组件都确定了之后,用户请求的处理流程,也就随之尘埃落定了。
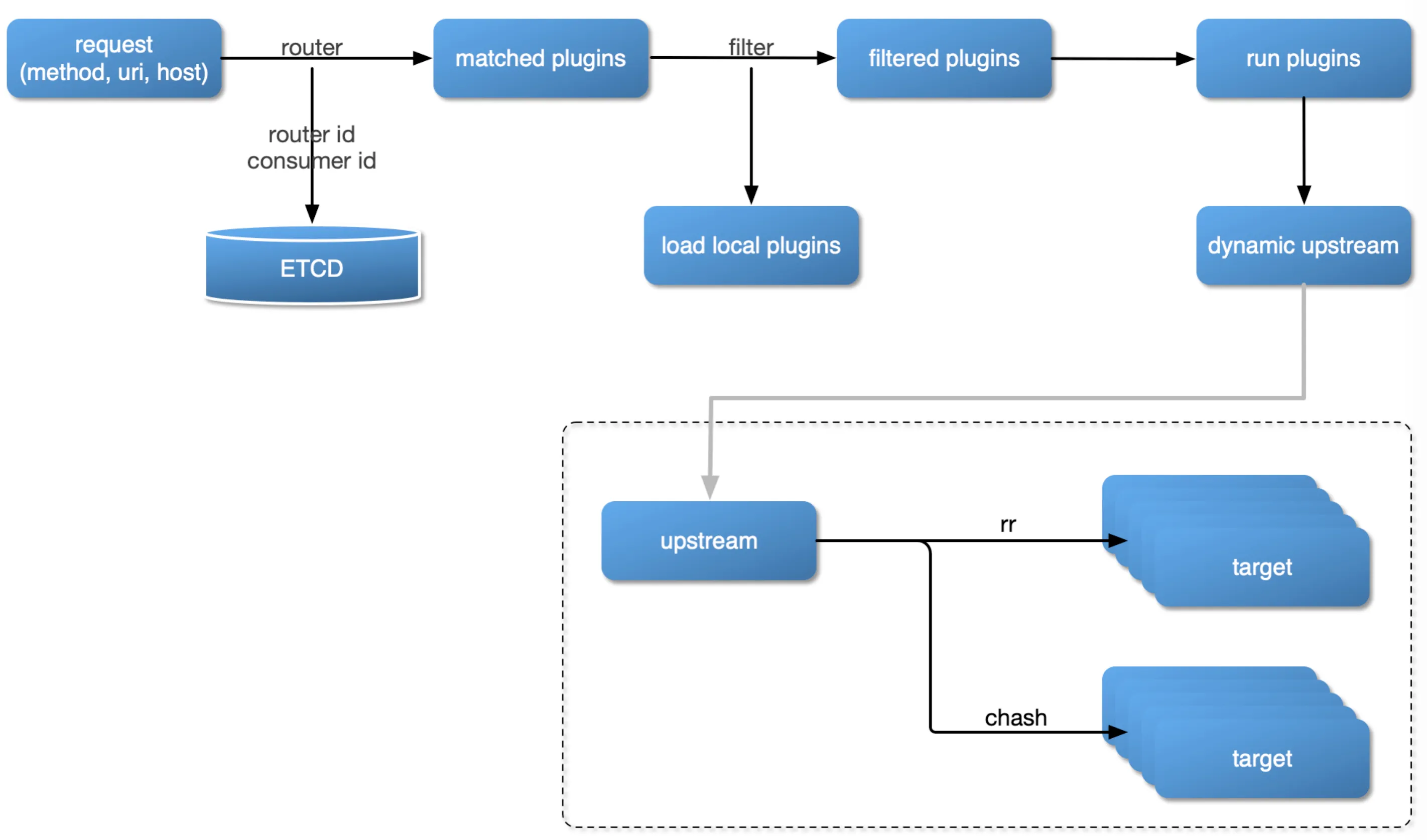
从这个图中我们可以看出,当一个用户请求进入 API 网关时,
- 首先,会根据请求的方法、uri、host、请求头等条件,去路由规则中进行匹配。如果命中了某条路由规则,就会从 etcd 中获取对应的插件列表。
- 然后,和本地开启的插件列表进行交集,得到最终可以运行的插件列表。
- 再接着,根据插件的优先级,逐个运行插件。
- 最后,根据上游的健康检查和负载均衡算法,把这个请求发送给上游。
实现
Nginx 配置和初始化
我们知道,API 网关是用来处理流量入口的,所以我们首先需要在 Nginx.conf 中做简单的配置,让所有的流量都通过网关的 Lua 代码来处理。
server {
listen 9080;
init_worker_by_lua_block {
apisix.http_init_worker()
}
location / {
access_by_lua_block {
apisix.http_access_phase()
}
header_filter_by_lua_block {
apisix.http_header_filter_phase()
}
body_filter_by_lua_block {
apisix.http_body_filter_phase()
}
log_by_lua_block {
apisix.http_log_phase()
}
}
}在这个示例中,我们监听了 9080 端口,并通过 location / 的方式,把这个端口的所有请求都拦截下来,并依次通过 access、rewrite、header filter、body filter 和 log 这几个阶段进行处理,在每个阶段中都会去调用对应的插件函数。其中, rewrite 阶段便是在 apisix.http_access_phase 函数中合并处理的。
而对于系统初始化的工作,我们放在了 init_worker 阶段来处理,这其中包含了读取各项配置参数、预制 etcd 中的目录、从 etcd 中获取插件列表、对于插件按照优先级进行排序等。我这里列出了关键部分的代码并进行讲解,当然,你可以在 GitHub 上看到更完整的初始化函数。
function _M.http_init_worker()
-- 分别初始化路由、服务和插件这三个最重要的部分
router.init_worker()
require("apisix.http.service").init_worker()
require("apisix.plugin").init_worker()
end匹配路由
在最开始的 access 阶段里面,我们首先需要做的就是匹配路由,根据请求中携带 uri、host、args、cookie 等,来和已经设置好的路由规则进行匹配:
router.router_http.match(api_ctx)对外暴露的,其实只有上面一行代码,这里的api_ctx 中存放的就是 uri、host、args、cookie 这些请求的信息。而具体的 match 函数的实现,就用到了我们前面提到过的 lua-resty-radixtree。如果没有命中,就说明这个请求并没有设置与之对应的上游,就会直接返回 404。
local router = require("resty.radixtree")
local match_opts = {}
function _M.match(api_ctx)
-- 从 ctx 中获取请求的参数,作为路由的判断条件
match_opts.method = api_ctx.var.method
match_opts.host = api_ctx.var.host
match_opts.remote_addr = api_ctx.var.remote_addr
match_opts.vars = api_ctx.var
-- 调用路由的判断函数
local ok = uri_router:dispatch(api_ctx.var.uri, match_opts, api_ctx)
-- 没有命中路由就直接返回 404
if not ok then
core.log.info("not find any matched route")
return core.response.exit(404)
end
return true
end加载插件
local plugins = core.tablepool.fetch("plugins", 32, 0)
-- etcd 中的插件列表和本地配置文件中的插件列表进行交集运算
api_ctx.plugins = plugin.filter(route, plugins)
-- 依次运行插件在 rewrite 和 access 阶段挂载的函数
run_plugin("rewrite", plugins, api_ctx)
run_plugin("access", plugins, api_ctx)在这段代码中,我们首先通过 table pool 的方式,申请了一个长度为 32 的 table,这是我们之前介绍过的性能优化技巧。然后便是插件的过滤函数。你可能疑惑,为什么需要这一步呢?在插件的 init worker 阶段,我们不是已经从 etcd 中获取插件列表并完成排序了吗?
事实上,这里的过滤是和本地配置文件来做对比的,主要有下面两个原因。
- 第一,新开发的插件需要灰度来发布,这时候新插件在 etcd 的列表中存在,但只在部分网关节点中处于开启状态。所以,我们需要额外做一次交集的运算。
- 第二,为了支持 debug 模式。终端的请求经过了哪些插件的处理?这些插件的加载顺序是什么?这些信息在调试的时候会很有用,所以在过滤函数中也会判断其是否处于 debug 模式,并在响应头中记录下这些信息。
因此,在 access 阶段的最后,我们会把这些过滤好的插件,按照优先级逐个运行,如下面这段代码所示:
local function run_plugin(phase, plugins, api_ctx)
for i = 1, #plugins, 2 do
local phase_fun = plugins[i][phase]
if phase_fun then
-- 最核心的调用代码
phase_fun(plugins[i + 1], api_ctx)
end
end
return api_ctx
end你可以看到,在遍历插件的时候,我们是以 2 为间隔进行的,这是因为每个插件都会有两个部分组成:插件对象和插件的配置参数。现在,我们来看上面示例代码中最核心的那一行代码:
phase_fun(plugins[i + 1], api_ctx)单独看这行代码会有些抽象,我们用一个具体的 limit_count 插件来替换一下,就会清楚很多:
limit_count_plugin_rewrite_function(conf_of_plugin, api_ctx)到这里,API 网关的整体流程,我们就实现得差不多了。这些代码都在同一个代码文件中。
编写插件
以 limit-count 这个限制请求数的插件为例,它的完整实现只有 60 多行代码。
首先,引入 lua-resty-limit-traffic ,作为限制请求数的基础库:
local limit_count_new = require("resty.limit.count").new然后,使用 json schema ,来定义这个插件的参数有哪些:
local schema = {
type = "object",
properties = {
count = {type = "integer", minimum = 0},
time_window = {type = "integer", minimum = 0},
key = {type = "string",
enum = {"remote_addr", "server_addr"},
},
rejected_code = {type = "integer", minimum = 200, maximum = 600},
},
additionalProperties = false,
required = {"count", "time_window", "key", "rejected_code"},
}插件的这些参数,和大部分 resty.limit.count 的参数是对应的,其中包含了限制的 key、时间窗口的大小、限制的请求数。另外,插件中增加了一个参数: rejected_code,在请求被限速的时候返回指定的状态码。
最后一步,把插件的处理函数挂载到 rewrite 阶段:
function _M.rewrite(conf, ctx)
-- 从缓存中获取 limit count 的对象,如果没有就使用 `create_limit_obj` 函数新建并缓存
local lim, err = core.lrucache.plugin_ctx(plugin_name, ctx, create_limit_obj, conf)
-- 从 ctx.var 中获取 key 的值,并和配置类型和配置版本号一起组成新的 key
local key = (ctx.var[conf.key] or "") .. ctx.conf_type .. ctx.conf_version
-- 进入限制的判断函数
local delay, remaining = lim:incoming(key, true)
if not delay then
local err = remaining
-- 如果超过阈值,就返回指定的状态码
if err == "rejected" then
return conf.rejected_code
end
core.log.error("failed to limit req: ", err)
return 500
end
-- 如果没有超过阈值,就放行,并设置对应响应头
core.response.set_header("X-RateLimit-Limit", conf.count,
"X-RateLimit-Remaining", remaining)
end上面的代码中,进行限制判断的逻辑只有一行,其他的都是来做准备工作和设置响应头的。如果没有超过阈值,就会继续按照优先级运行下一个插件。